4.4. GPU Computing#
4.4.1. Machine Learning Parallelism Approaches on GPUs#
The scaling of machine learning (ML) workloads in HPC environments can be achieved through various parallelism approaches. This section outlines the primary methods for parallelizing ML computations.
4.4.1.1. Data Parallelism#
Involves splitting the dataset into smaller batches that are processed in parallel across different GPUs. Each GPU trains a copy of the model on its subset of the data, and the results are aggregated to update the model.
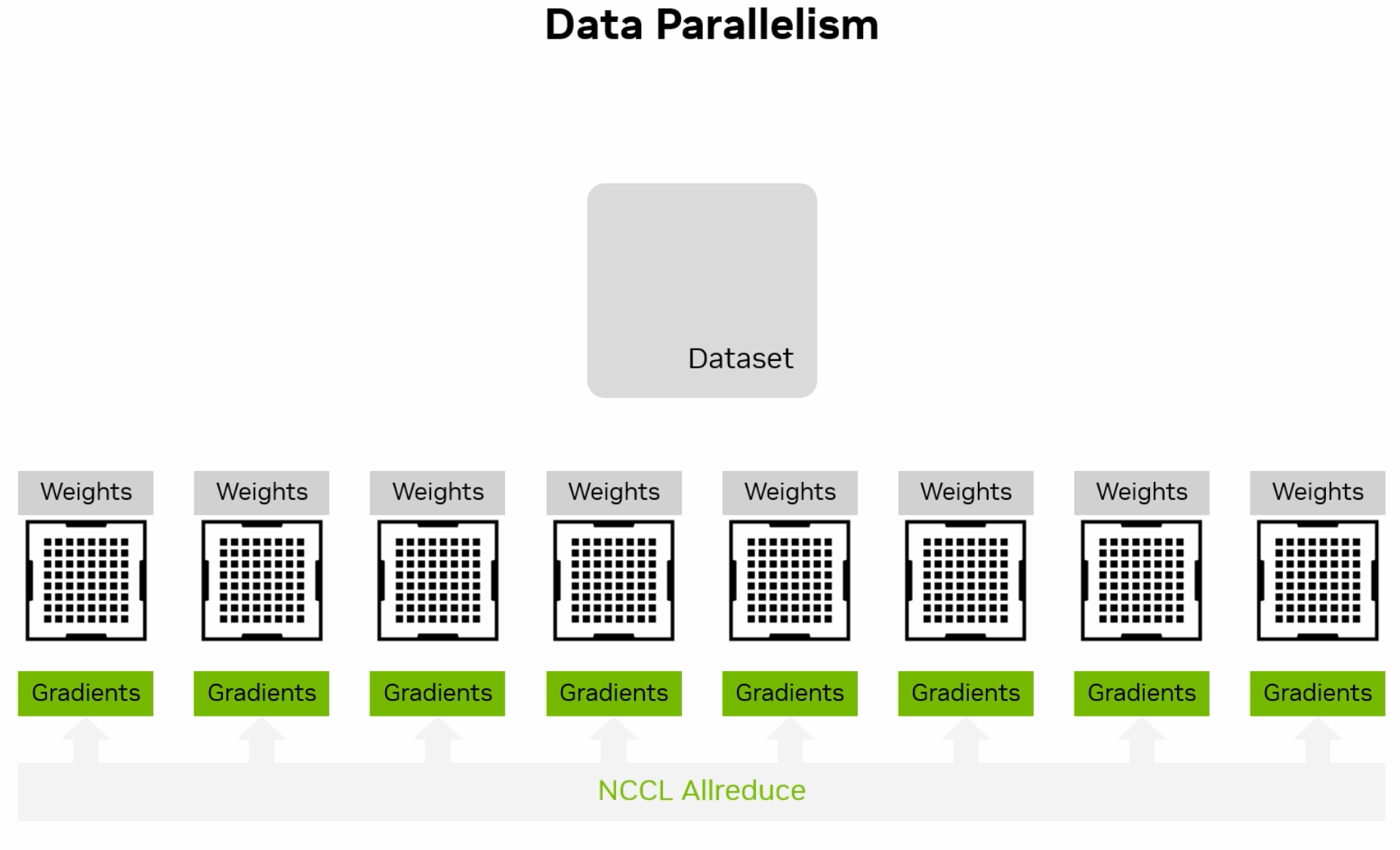
Fig. 4.4 (Credit: nvidia.com)#
4.4.1.2. Model Parallelism#
The model’s parameters are divided across multiple GPUs. This approach is useful for training large models that cannot fit into the memory of a single GPU. GPUs work on different parts of the model simultaneously.
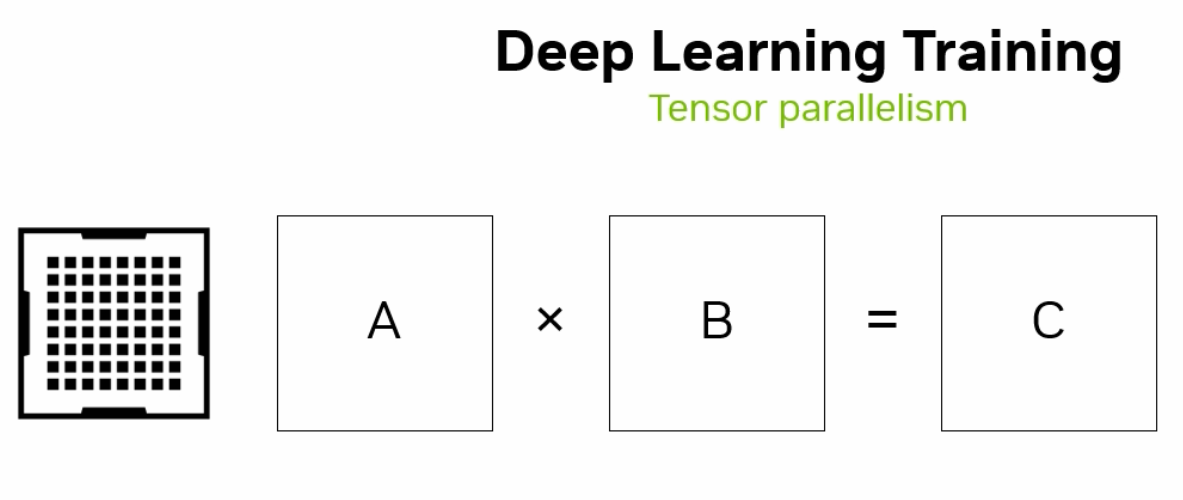
Fig. 4.5 Model Parallelism Diagram (Credit: nvidia.com)#
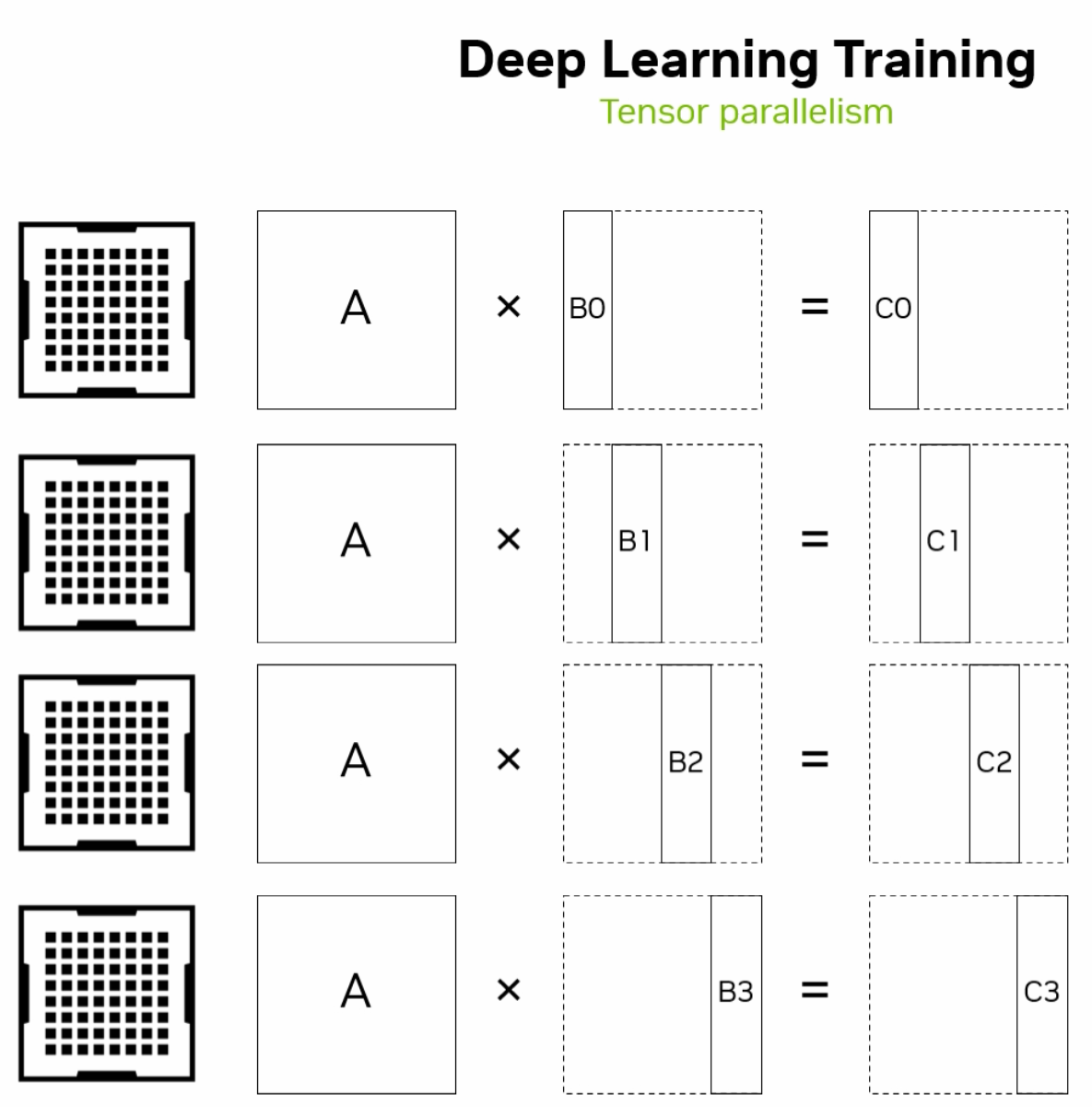
Fig. 4.6 Model Parallelism Diagram (Credit: nvidia.com)#
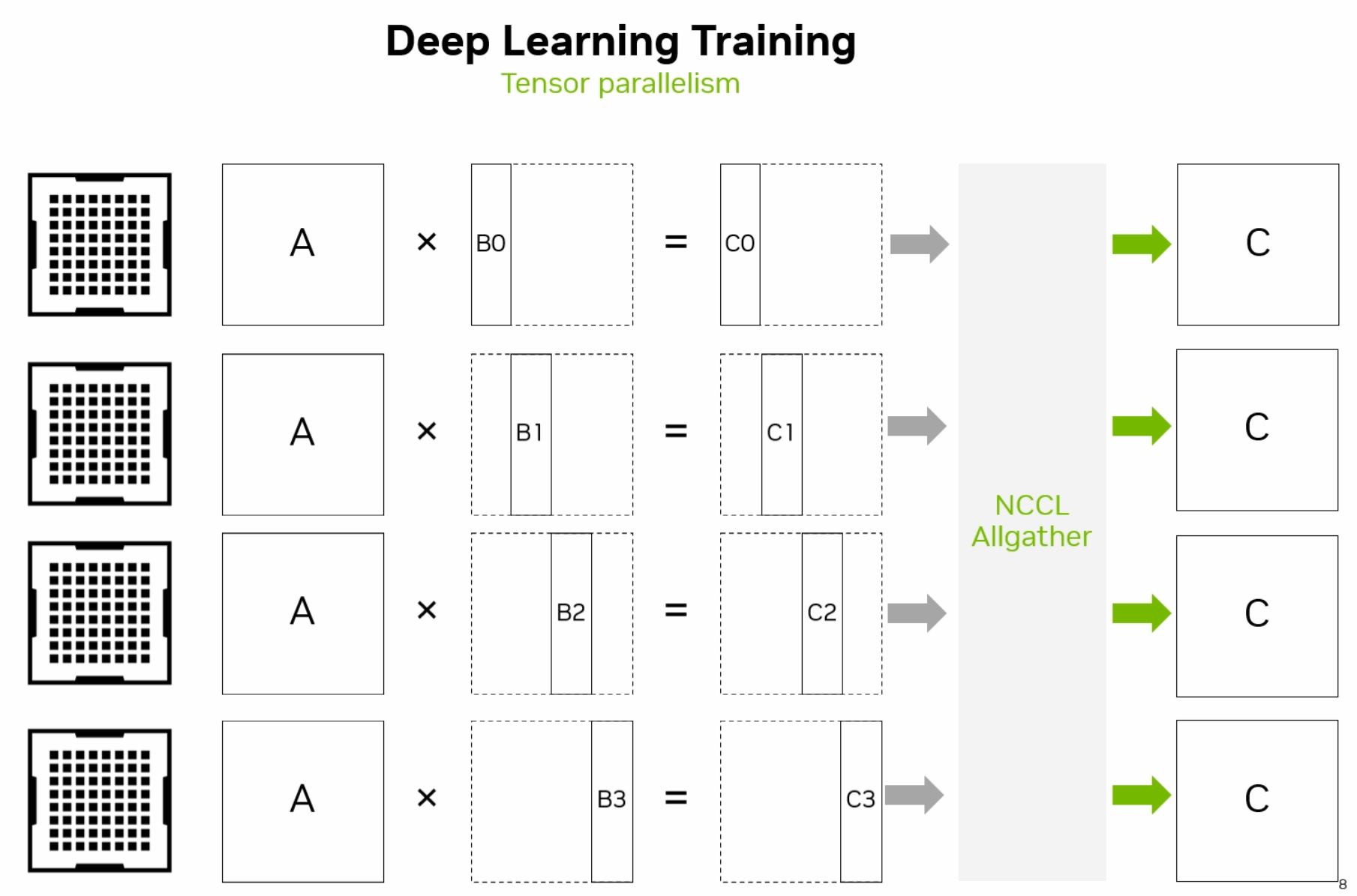
Fig. 4.7 Model Parallelism Diagram (Credit: nvidia.com)#
4.4.1.3. Pipeline Parallelism#
Combines aspects of data and model parallelism by splitting the model into stages that are processed in a pipeline fashion. Each stage of the model is processed on different GPU, allowing for efficient parallel processing of large models and datasets.
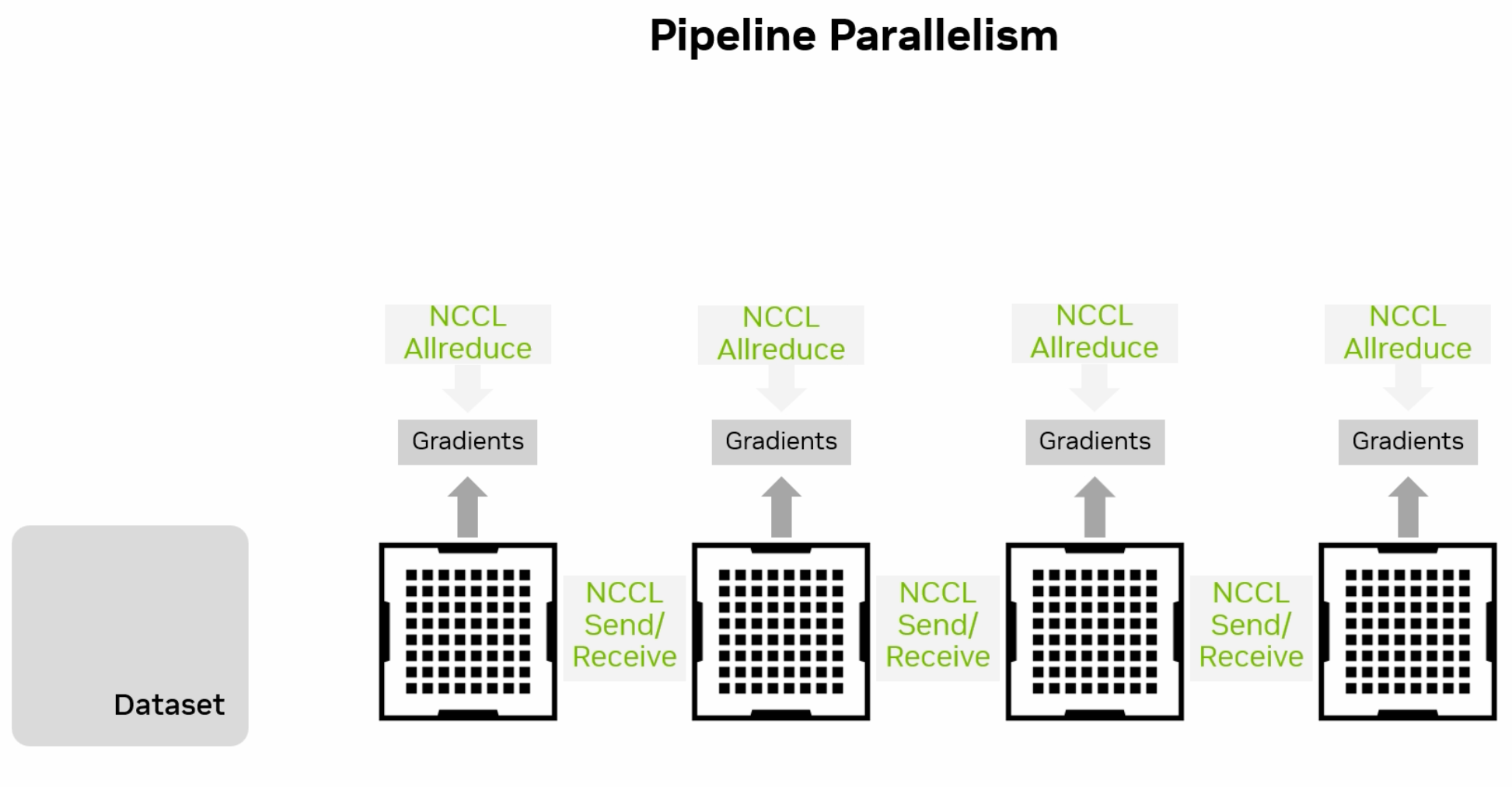
Fig. 4.8 Pipeline Parallelism Diagram (Credit: nvidia.com)#
4.4.1.4. Hybrid Parallelism#
The hybrid model is a combination of data, model, and pipeline parallelism. It combines these techniques to benefit from the scalability of data parallelism, the memory efficiency of model parallelism, and the throughput efficiency of pipeline parallelism. For instance, a large model can be divided into segments (model parallelism), each segment can be replicated across multiple devices (data parallelism), and different segments can process different batches of data simultaneously (pipeline parallelism).
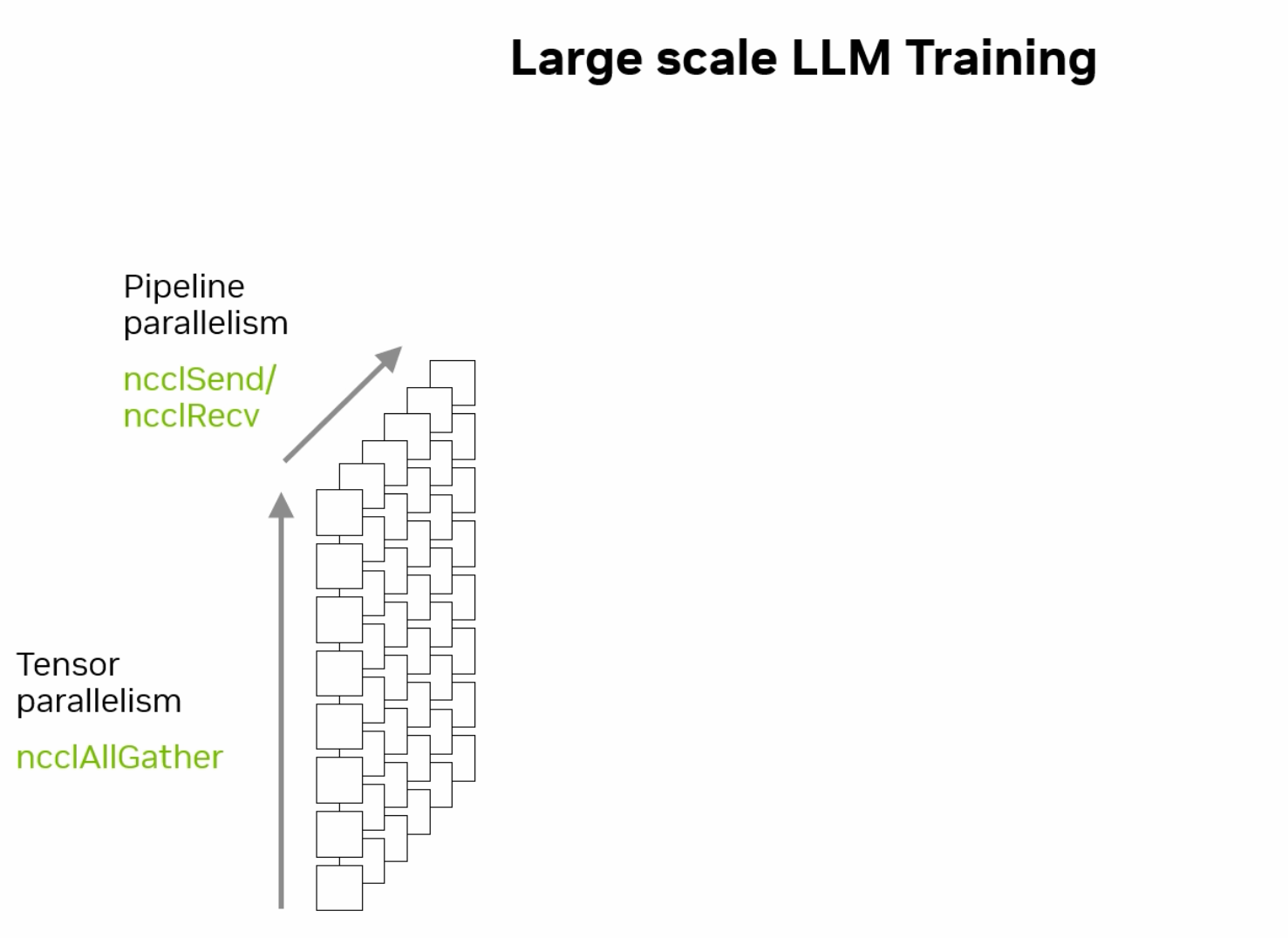
Fig. 4.9 Hybrid Parallelism Diagram (Credit: nvidia.com)#
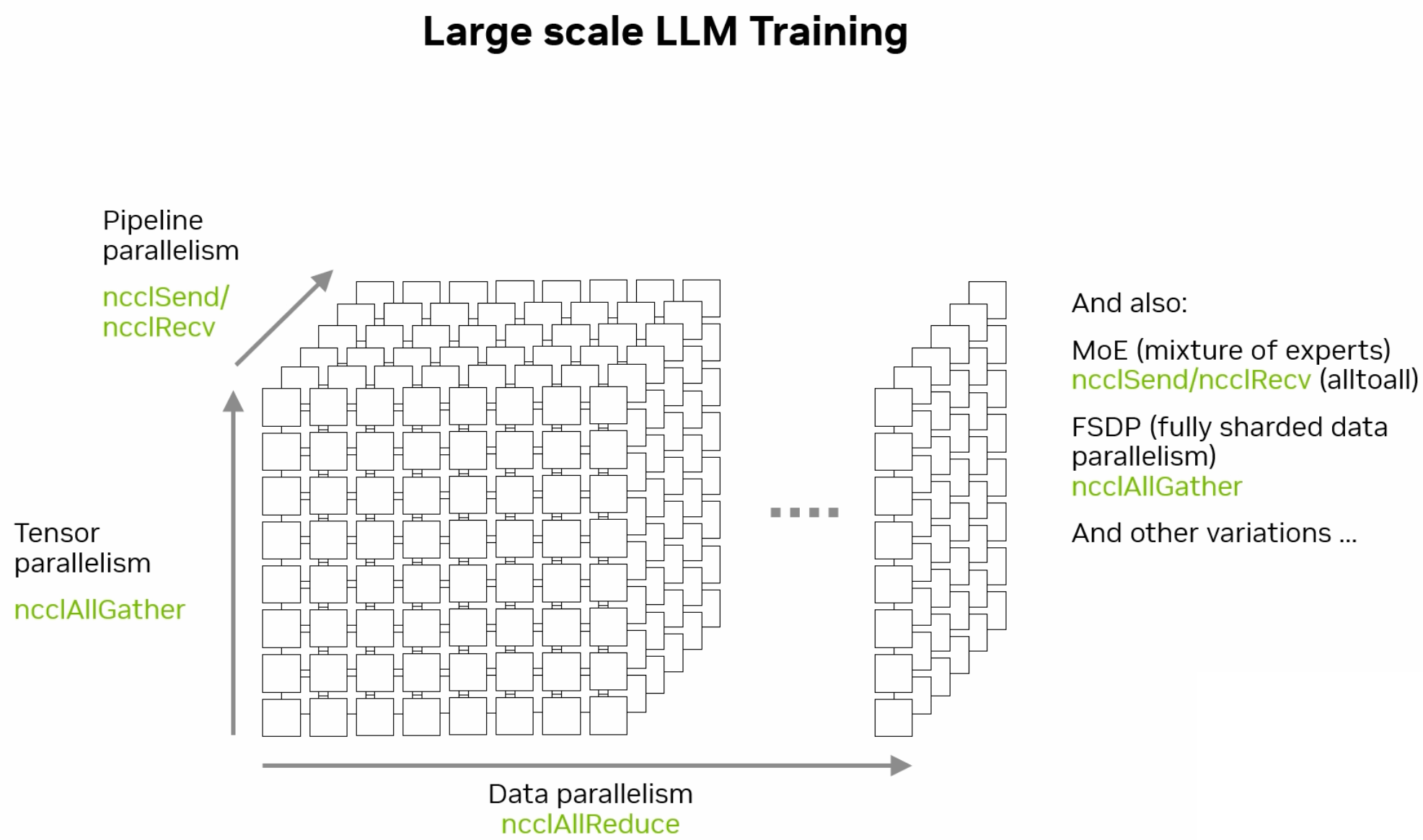
Fig. 4.10 Hybrid Parallelism Diagram (Credit: nvidia.com)#
These parallelism approaches leverage the computational power of HPC to tackle the complexities of training and deploying large-scale ML models, ensuring efficient use of resources and reducing computation time.
4.4.1.5. Comparison Table#
The following table highlights the core aspects and trade-offs of using data, model, pipeline, and hybrid parallelism approaches with GPUs for machine learning tasks.
Approach |
Features |
Pros |
Cons |
|---|---|---|---|
Data Parallelism |
Splits dataset, processes chunks on different GPUs. |
- Scalable |
- High communication overhead |
Model Parallelism |
Different parts of the model on multiple GPUs. |
- Trains large models |
- Complex dependencies |
Pipeline Parallelism |
Model stages across GPUs, data processed in sequence. |
- Efficient resource use |
- Scheduling complexity |
Hybrid Parallelism |
Combines all three methods for optimization. |
- Minimizes overhead |
- High complexity |